Техники тест-дизайна
Техники тест-дизайна
Тест-дизайн и техники тест-дизайна (Test Design and Software Testing Techniques)
Проектирование теста (test design): Процесс перевода общих причин тестирования в конкретные тестовые условия и тестовые сценарии. (ISTQB)
Причина тестирования (test objective): Причина или цель разработки и выполнения теста. (ISTQB)
Тестовое условие (test condition): Объект или событие в компоненте или системе, которое должно быть проверено одним или несколькими тестовыми наборами. Например: функция, транзакция, свойство, атрибут качества или структурный элемент. (ISTQB)
Тест-дизайн - важный этап STLС, а именно деятельность по получению и определению тестовых примеров из test objectives и test conditions. Проще говоря, цель тест-дизайна - создать максимально эффективный набор кейсов, покрывающий наиболее важные аспекты тестируемого ПО, т.е. минимизировать количество тестов, необходимых для нахождения большинства серьезных ошибок.
Тест дизайн — это этап процесса тестирования ПО, на котором проектируются и создаются тестовые сценарии (тест кейсы), в соответствии с определёнными ранее критериями качества и целями тестирования. Роли, ответственные за тест дизайн: • Тест аналитик — определяет «ЧТО тестировать?» • Тест дизайнер — определяет «КАК тестировать?»
Одним из наиболее важных аспектов теста является то, что он проверяет, выполняет ли система то, что она должна делать. Copeland говорит: “По сути, тестирование - это процесс сравнения того, что есть с тем, что должно быть”. Если мы просто введем какие-то данные и подумаем, что это было весело, я предполагаю, что с системой, вероятно, все в порядке, потому что она не крашнулась, но действительно ли мы ее тестируем? Beizer называет это «детским тестированием» (kiddie testing). Мы можем не знать каждый раз, какой правильный ответ в деталях, и иногда мы все равно можем получить некоторую выгоду от этого подхода, но на самом деле это не проверка. Чтобы знать, что система должна делать, нам нужен источник информации о правильном поведении системы - это называется «оракул» или тестовый оракул (test oracle). После того, как заданное входное значение было выбрано, тестировщику необходимо определить, каким будет ожидаемый результат ввода этого входа, и задокументировать его как часть тестового примера.
Давайте проясним. Требования или пользовательские истории с критериями приемлемости (формы test basis) определяют, что вы должны тестировать (test objects and test conditions), и исходя из этого, вы должны выяснить способ тестирования, то есть спроектировать тестовые примеры. Один из наиболее важных вопросов заключается в следующем: какие факторы влияют на успешный дизайн теста? Если вы читаете разные блоги, статьи или книги, вы найдете примерно следующее:
- Время и бюджет, доступные для тестирования;
- Соответствующие знания и опыт вовлеченных людей;
- Определен целевой уровень покрытия (измерение уровня достоверности (measuring the confidence level));
- Способ организации процесса разработки программного обеспечения (например, водопад или гибкая разработка);
- Устанавливается соотношение методов создания тестов (например, ручных и автоматических);
Это неправда! Без достаточного времени и бюджета вы, вероятно, вообще не начнете ни одного проекта. Если у вас нет квалифицированных специалистов по тестированию программного обеспечения, включая дизайн тестов, то, вероятно, вы тоже не начнете проект. Однако, хороший дизайн теста включает три предварительных условия:
- Полная спецификация (Complete specification)(test bases);
- Анализ рисков и сложности (Risk and complexity analysis);
- Исторические данные ваших предыдущих разработок;
Требуются некоторые пояснения. Полная спецификация не означает безошибочную спецификацию, так как во время разработки теста можно найти и исправить множество проблем (предотвращение дефектов). Это только означает, что у нас есть все необходимые требования или в Agile разработке у нас есть все эпики, темы и пользовательские истории с критериями приемлемости (acceptance criteria). Существует минимальная ценность в одновременном рассмотрении затрат на тестирование и затрат на исправление дефектов, и цель хорошего тест-дизайна - выбрать подходящие методы тестирования, приближающиеся к этому минимуму. Это можно сделать, проанализировав сложность, риски и используя исторические данные. Таким образом, анализ рисков неизбежен для определения тщательности тестирования. Чем выше риск использования функции / объекта, тем более тщательное тестирование необходимо. То же самое можно сказать и о сложности кода. Для более рискованного или сложного кода мы должны сначала применить больше НЕкомбинаторных методов проектирования тестов вместо одного чисто комбинаторного.
Наше другое и правильное представление о дизайне тестирования состоит в том, что если у вас есть соответствующая спецификация (тестовая база) и надежный анализ рисков и сложности, то, зная ваши исторические данные, вы можете выполнить дизайн теста оптимальным образом. Вначале у вас нет исторических данных, и вы, вероятно, не достигнете оптимума. Нет проблем, давайте сделаем предварительную оценку. Например, если риск и сложность низкие, используйте только исследовательское тестирование. Если они немного выше, используйте исследовательское тестирование и простые методы, основанные на спецификациях, такие как классы эквивалентности с анализом граничных значений. Если риск высок, вы можете использовать исследовательское тестирование, комбинационное тестирование, предотвращение дефектов, статический анализ и обзоры (reviews).
Еще одно важное замечание. Критерии выбора тестов и адекватности тестовых данных различны. Первый - неотъемлемая часть любой техники тест-дизайна. Второй проверяет набор тестов. В результате процесса разработки тестов создаются независимые от реализации тестовые примеры, которые проверяют требования или пользовательские истории. Напротив, тесты, которые создаются на основе отсутствия покрытия по выбранным критериям адекватности тестовых данных, подтверждают проблемы, зависящие от реализации; однако это НЕ дизайн теста, это создание теста. Очень важно использовать метод «сначала тестирование» (test-first method), т. е. дизайн теста должен быть отправной точкой разработки. Дизайн тестов также очень эффективен для предотвращения дефектов, если он применяется до внедрения.
Итак, хороший процесс тест-дизайна выглядит так:
- Сбор информации, чтобы понять требования пользователей;
- Получение всех важных бизнес-сценариев;
- Создание тестовых сценариев для каждого производного критически важного бизнес-сценария;
- Назначение всех запланированных тестовых сценариев различным тестовым случаям;
Затем вам нужно будет выбрать технику тест-дизайна для каждого требования. На этом этапе, если все реализовано правильно, вы можете внести значительные изменения, которые чрезвычайно повлияют на ваш ROI.
Роли, ответственные за тест дизайн:
- Тест аналитик (test analyst) - определяет "ЧТО тестировать?":
- Исследует продукт:
- Понимание цели создания продукта;
- Какими способами цель должна достигаться;
- Какие и основные и вспомогательные возможности предоставляет продукт пользователям;
- Оценка, правильно ли понял разработчик заказчика.
- Составляет логическую карту продукта: Интеллект - карта - это техника представления любого процесса, события, мысли или идеи в систематизированной визуальной форме;
- Разбивает программный продукт на основные части:
- Система расчленяется только по одному, постоянному для всех уровней признаку (Они должны отвечать на один и тот же вопрос, по отношению к своему родителю);
- Вычленяемые подсистемы должны взаимно исключать друг друга, а в сумме - характеризовать систему;
- На каждом уровне рекомендуется использовать не более 7 подсистем;
- Расставляет приоритеты для тестирования:
- Требования клиента;
- Степень риска;
- Сложность системы;
- Временные ограничения;
- Исследует продукт:
- Тест дизайнер - определяет "КАК тестировать?";
Попросту говоря, задача тест аналитиков и дизайнеров сводится к тому, чтобы используя различные стратегии и техники тест дизайна, создать набор Test case, обеспечивающий оптимальное тестовое покрытие тестируемого приложения. Однако, на большинстве проектов эти роли не выделяется, а доверяется обычным тестировщикам, что не всегда положительно сказывается на качестве тестов, тестировании и, как из этого следует, на качестве ПО (конечного продукта).
Техники тест дизайна
• Эквивалентное Разделение (Equivalence Partitioning — EP). Как пример, у вас есть диапазон допустимых значений от 1 до 10, вы должны выбрать одно верное значение внутри интервала, скажем, 5, и одно неверное значение вне интервала — 0.
• Анализ Граничных Значений (Boundary Value Analysis — BVA). Если взять пример выше, в качестве значений для позитивного тестирования выберем минимальную и максимальную границы (1 и 10), и значения больше и меньше границ (0 и 11). Анализ Граничный значений может быть применен к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
• Причина / Следствие (Cause/Effect — CE). Это, как правило, ввод комбинаций условий (причин), для получения ответа от системы (Следствие). Например, вы проверяете возможность добавлять клиента, используя определенную экранную форму. Для этого вам необходимо будет ввести несколько полей, таких как «Имя», «Адрес», «Номер Телефона» а затем, нажать кнопку «Добавить» — это «Причина». После нажатия кнопки «Добавить», система добавляет клиента в базу данных и показывает его номер на экране — это «Следствие».
• Предугадывание ошибки (Error Guessing — EG). Это когда тестировщик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «пользователь должен ввести код». Тестировщик будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? », и так далее. Это и есть предугадывание ошибки.
• Исчерпывающее тестирование (Exhaustive Testing — ET) — это крайний случай. В пределах этой техники вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода не представляется возможным, из-за огромного количества входных значений.
• Попарное тестирование (Pairwise Testing) — это техника формирования наборов тестовых данных. Сформулировать суть можно, например, вот так: формирование таких наборов данных, в которых каждое тестируемое значение каждого из проверяемых параметров хотя бы единожды сочетается с каждым тестируемым значением всех остальных проверяемых параметров.
Допустим, какое-то значений (налог) для человека рассчитывается на основании его пола, возраста и наличия детей — получаем три входных параметра, для каждого из которых для тестов выбираем каким-то образом значения. Например: пол — мужской или женский; возраст — до 25, от 25 до 60, более 60; наличие детей — да или нет. Для проверки правильности расчётов можно, конечно, перебрать все комбинации значений всех параметров:
№ пол возраст дети 1 мужчина до 25 детей нет 2 женщина до 25 детей нет 3 мужчина 25-60 детей нет 4 женщина 25-60 детей нет 5 мужчина старше 60 детей нет 6 женщина старше 60 детей нет 7 мужчина до 25 дети есть 8 женщина до 25 дети есть 9 мужчина 25-60 дети есть 10 женщина 25-60 дети есть 11 мужчина старше 60 дети есть 12 женщина старше 60 дети есть А можно решить, что нам не нужны сочетания значений всех параметров со всеми, а мы хотим только убедиться, что мы проверим все уникальные пары значений параметров. Т.е., например, с точки зрения параметров пола и возраста мы хотим убедиться, что мы точно проверим мужчину до 25, мужчину между 25 и 60, мужчину после 60, а также женщину до 25, женщину между 25 и 60, ну и женщину после 60. И точно так же для всех остальных пар параметров. И таким образом, мы можем получить гораздо меньше наборов значений (в них есть все пары значений, правда некоторые дважды):
№ пол возраст дети 1 мужчина до 25 детей нет 2 женщина до 25 дети есть 3 мужчина 25-60 дети есть 4 женщина 25-60 детей нет 5 мужчина старше 60 детей нет 6 женщина старше 60 дети есть Такой подход примерно и составляет суть техники pairwise testing — мы не проверяем все сочетания всех значений, но проверяем все пары значений.
Техники тест-дизайна (Software testing techniques)
- Cтатические (Static):
- Reviews:
- Неформальное ревью (Informal review)
- Прохождение (Walkthrough)
- Техническое ревью (Technical Review)
- Инспекция (Inspection)
- Статический анализ (Static Analysis):
- Поток данных (Data Flow)
- Поток управления (Control Flow)
- Путь (Path)
- Стандарты (Standards)
- Reviews:
- Динамические (Dynamic):
- Белый ящик (White-box, Structure-Based)
- Выражение (Statement)
- Решение (Decision)
- Ветвь (Branch)
- Условие (Condition)
- Конечный автомат (FSM)
- Основанные на опыте (Experience-based):
- Предугадывание ошибки (Error Guessing - EG);
- Исследовательское тестирование (Exploratory testing);
- Ad-hoc testing;
- Attack Testing;
- Черный ящик (Black-box, Specification-based):
- Эквивалентное Разделение (Equivalence Partitioning - EP)
- Анализ Граничных Значений (Boundary Value Analysis - BVA)
- Комбинаторные техники (Combinatorial Test Techniques)
- Переходы между состояниями (State transition)
- Случаи использования (Use case testing)
- Domain testing
- Decision Table Testing
- Classification Tree Method
- State Transition Testing
- Cause-Effect Graphing
- Scenario Testing
- Random Testing
- Syntax Testing
- Check List Based Testing
- Risk-Based Testing
- User Journey Test
- Белый ящик (White-box, Structure-Based)
Static - Reviews
Рецензирование (review): Оценка состояния продукта или проекта с целью установления расхождений с запланированными результатами и для выдвижения предложений по совершенствованию. Примерами рецензирования могут служить: управленческое рецензирование, неформальное рецензирование, технический анализ, инспекция и разбор. (ISTQB)
Неформальное рецензирование (informal review): Рецензирование, которое не основано на формальной (документированной) процедуре. (ISTQB)
Разбор (walkthrough): Пошаговый разбор, проводимый автором документа для сбора информации и обеспечения одинакового понимания содержания документа. (IEEE 1028)
Равноправный анализ (peer review): Рецензирование разрабатываемого программного продукта, проводящееся сотрудниками компании-разработчика с целью нахождения дефектов и внесение улучшений. Примерами рецензирования являются: инспекция, технический анализ и разбор. (ISTQB)
Инспекция (inspection): Тип равноправного анализа, основанный на визуальной проверке документов для поиска ошибок. Например, нарушение стандартов разработки и несоответствие документации более высокого уровня. Наиболее формальная методика рецензирования и поэтому всегда основывается на документированной процедуре. (IEEE 610, IEEE 1028). См. также равноправный анализ.
Методы статического тестирования делятся на две основные категории, одной из которых являются ревью. Ранжирование по уровню формальности:
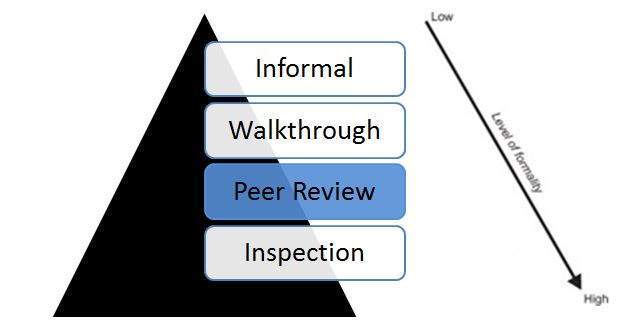
Экспертные обзоры (Peer Reviews):
Рецензирование - это стандартизированный метод проверки правильности исходного кода при разработке программного обеспечения, который проводится для выявления дефектов на ранних этапах жизненного цикла и которые не могут быть обнаружены с помощью методов тестирования черного ящика.
Прохождение/просмотр/пошаговый разбор (walkthrough ):
Метод проведения неформального группового / индивидуального просмотра. В walkthrough автор описывает и объясняет рабочий продукт на неформальной встрече своим коллегам или руководителю, чтобы получить обратную связь. Здесь проверяется применимость предложенного решения для рабочего продукта. Либо рабочий продукт проверяется на наличие дефектов несколькими лицами, кроме человека, который его фактически произвел;
Технический обзор (Technical Review):
Это метод более высокого уровня по сравнению с inspection или walkthrough, поскольку он также включает в себя управление. Этот метод используется для оценки (assess and evaluate) продукта путем проверки его соответствия стандартам разработки, руководствам и спецификациям. У него нет определенного процесса, и большая часть работы выполняется модератором, как описано ниже:
- Модератор собирает и раздает материал и документацию всем членам команды;
- Модератор также готовит набор показателей для оценки продукта в соответствии со спецификациями и уже установленными стандартами и гайдлайнами:
- последовательность;
- документация;
- соблюдение стандартов;
- полнота;
- определение проблемы и требования (? problem definition and requirements);
- Результаты фиксируются в документе, который включает как дефекты, так и предложения;
- Наконец, устраняются дефекты и учитываются предложения по улучшению продукта;
Инспекция:
Инспекция определяется как наиболее формальная, тщательная, глубокая групповая проверка, направленная на выявление проблем как можно ближе к их исходной точке. Процесс проверки выполняется на ранних этапах SDLC и применяется к определенной части продукта, такой как SRS, код, дизайн продукта. и т. д. Это включает в себя ручное изучение различных компонентов продукта на более ранних этапах. Инспекционная деятельность следует определенному процессу, и участники играют четко определенные роли. Инспекционная группа состоит из трех-восьми человек, которые играют роли модератора, автора, читателя, записывающего и инспектора. Например, разработчик может выступать в качестве инспектора во время проверки кода, в то время как представитель по обеспечению качества может действовать как исполнитель стандартов.
Software inspection process:
- Планирование встречи: на этом этапе основное внимание уделяется определению продукта, подлежащего инспекции, и цели этой инспекции. На этом этапе назначается модератор, который управляет всем процессом. Назначенный модератор проверяет, готов продукт к инспекции или нет. Модератор также выбирает инспекционную группу и назначает им их роли. Модератор также планирует инспекционную встречу и раздает необходимые материалы инспекционной группе;
- Обзор: на этом этапе инспекционной группе предоставляется вся справочная информация для инспекционного совещания. Автор, который является программистом или дизайнером, ответственным за разработку продукта, представляет свою логику и рассуждения о продукте, включая функции продукта, его предполагаемое назначение и подход или концепцию, использованные при его разработке. Удостоверяется, что каждый член инспекционной группы понял и знаком с задачами и целью инспекционного совещания, которое должно быть проведено;
- Индивидуальная подготовка участников: на этом этапе члены инспекционной группы индивидуально готовятся к инспекционной встрече, изучая материалы, предоставленные на более ранних этапах. Члены команды выявляют потенциальные ошибки или недочеты в продукте и записывают их в журнал. Журнал передается модератору. Затем модератор собирает все журналы, полученные от участников, и отправляет их автору. Инспектор - лицо, ответственное за проверку и выявление ошибок и несоответствий в документах или программах, проверяет продукт и записывает все обнаруженные в нем проблемы (как общие, так и специфические). Инспектор записывает проблемы или issues в журнал вместе со временем, затраченным на подготовку. Модератор просматривает логи, чтобы проверить, готова ли команда к инспекционной встрече или нет. Наконец, модератор отправляет автору все скомпилированные логи;
- Инспекционная встреча (Inspection Meeting): на этом этапе автор обсуждает вопросы, поднятые членами команды в скомпилированном журнале. Участники приходят к решению, является ли поднятый вопрос ошибкой или нет. Модератор завершает встречу и подводит итоги встречи - это список ошибок, обнаруженных в продукте, которые должен устранить автор.
- Переделка: доработка проводится автором согласно сводному списку, представленному модератором на предыдущем этапе. Автор исправляет все ошибки и сообщает модератору;
- Follow - up: модератор проверяет, все ли ошибки устранены или нет. Затем модератор готовит отчет. Если все ошибки исправлены и устранены, модератор выпускает документ. В противном случае в отчет добавляются нерешенные вопросы и назначается еще одно инспекционное собрание;

Static - Static Analysis
Статический анализ (static analysis): Анализ артефактов разработки программного обеспечения, таких как требования или программный код, проводимый без исполнения этих программных артефактов. Статический анализ обычно выполняется при помощи вспомогательных инструментов. (ISTQB)
Статический анализ - это анализ программных артефактов, таких как программный код (или требования, дизайн), выполняемый статически, т.е. без запуска и, очевидно, методом белого ящика. Основная цель этого анализа - как можно раньше найти ошибки, независимо от того, могут ли они вызывать отказы (failures). Как и в случае с обзорами (reviews), статический анализ обнаруживает ошибки (bugs), а не отказы. Обычно статический анализ проводят до формальной проверки, даже до unit testing, путём добавления этих проверок специалистами DevOps в пайплайн проекта. Статический анализ не связан с динамическими свойствами требований, дизайна и кода, такими как покрытие тестами (test coverage). Существует множество инструментов для статического анализа, которые в основном используются разработчиками до или во время тестирования компонентов или интеграции (чаще новые и измененные классы и функции), а также дизайнерами во время моделирования программного обеспечения. Инструменты могут отображать не только структурные атрибуты, такие как глубина вложенности или число цикломатической сложности и проверка на соответствие стандартам кодирования, но также графические изображения потока управления, взаимосвязи данных и количество отдельных путей от одной строки кода к другой. Информация может использоваться вплоть до формальных методов, которые математически подтверждают свойства данной программы.
Инструменты помогают в выявлении следующих дефектов:
- Неиспользуемые переменные;
- Части кода, которые никогда не выполнятся;
- Бесконечные циклы;
- Переменная с неопределенным значением;
- Неправильный синтаксис;
- Несогласованные интерфейсы между модулями и компонентами, такие как неправильное использование объекта, метода или функции, включая неправильные параметры;
- Уязвимости безопасности, такие как проблемы безопасности, связанные с переполнением буфера, возникающим из-за невозможности проверить длину буфера перед копированием в буфер;
- Различные типы нарушения стандартов программирования, как нарушения, создающие риск фактического сбоя, так и нарушения, которые усложняют тестирование, анализ и поддерживаемость кода;
Методы статического анализа:
Анализ управления (Control Analysis)
Фокусируется на изучении элементов управления, используемых в структуре вызовов, анализе потока управления и анализе переходов состояний (calling structure, control flow analysis and state transition analysis). Структура вызова связана с моделью путем идентификации вызовов и их структуры. Вызывающая структура может быть процессом, подпрограммой, функцией или методом. Анализ потока управления проверяет последовательность передачи управления и может выявить неэффективные конструкции в модели. Создается граф модели (CFG - Control Flow Graph), в котором условные ветви и стыки модели представлены узлами. По итогам также можно рассчитать цикломатическую сложность программы. Для анализа потока управления могут быть использованы: Абстрактная интерпретация, Удовлетворение ограничений, Типизация данных;
Анализ данных (Data Analysis)
Обеспечивает правильную работу с объектами данных, такими как структуры данных и связанные списки. Кроме того, этот метод также обеспечивает правильное использование определенных данных. Анализ данных включает два метода, а именно: зависимость данных и анализ потока данных (data dependency and data flow analysis). Зависимость данных необходима для оценки точности синхронизации между несколькими процессорами. Анализ потока данных проверяет определение и контекст переменных. Виды анализа потока данных:
- Reaching Definitions;
- Available Expressions;
- Constant Propagation;
- Very Busy Expressions;
- Live Variables;
- Use-Definition & Definition-Use;
- Анализ неисправностей / отказов (Fault/Failure Analysis): анализирует неисправности (некорректный компонент) и отказ (некорректное поведение компонента модели) в модели. Этот метод использует описание преобразования ввода-вывода для определения условий, являющихся причиной сбоя. Для определения отказов в определенных условиях проверяется проектная спецификация модели (model design specification);
- Анализ интерфейса (Interface Analysis): проверяет взаимодействующие и распределенные модели для проверки кода (This software verifies and verifies interactive and distribution simulations to check the code). Существует два основных метода анализа интерфейса, и анализ пользовательского интерфейса исследует интерфейсы подмоделей и определяет точность структуры интерфейса. Анализ пользовательского интерфейса исследует модель пользовательского интерфейса и меры предосторожности, предпринимаемые для предотвращения ошибок во время взаимодействия пользователя с моделью. Этот метод также фокусируется на том, насколько точно интерфейс интегрирован в общую модель и симуляцию.
Анализ потока управления (Control Flow Analysis) и анализ потока данных (Data Flow Analysis) взаимозависимы: чтобы получить точные результаты для анализа потока данных, необходимо учитывать поток управления (поскольку порядок операций влияет на возможные значения данных в конкретном месте программы). Чтобы получить точные результаты для анализа потока управления, необходимо учитывать поток данных, поскольку поток динамического управления (решение, принимаемое во время выполнения) зависит от значений данных в конкретных местах программы. Однако эти два анализа преследуют разные цели.
Граф потока управления (Control Flow Graph)
Граф потока управления (CFG) - это графическое представление потока управления или вычислений во время выполнения программ или приложений. Графы потока управления в основном используются в статическом анализе, а также в приложениях-компиляторах, поскольку они могут точно представлять поток внутри программного модуля. Характеристики графа потока управления:
- Граф потока управления процессно-ориентированный (process oriented);
- Граф потока управления показывает все пути, которые можно пройти во время выполнения программы;
- Граф потока управления - это ориентированный граф;
- Рёбра в CFG изображают пути потока управления, а узлы в CFG изображают базовые блоки.
Полное описание возможных элементов графа.
Цикломатическая сложность (Cyclomatic Complexity)
Цикломатическая сложность - это метрика для измерения сложности кода, основанная на графе потока управления. Независимый путь определяется как путь, имеющий хотя бы одно ребро, которое ранее не проходило ни в одном другом пути.
Определение из книги Ли Копланда - “A Practitioner's Guide to Software Test Design”, Главы 10:
Цикломатическая сложность - это конечное минимальное количество независимых, нецикличных маршрутов (называемых основными маршрутами), которые могут образовывать все возможные линейные пути в программном модуле.
Цикломатическая сложность может быть рассчитана относительно функций, модулей, методов или классов в программе как вручную, так и с помощью автоматизированных инструментов.
Математически цикломатическая сложность структурированной программы определяется с помощью ориентированного графа, узлами которого являются блоки программы, соединенные ребрами, если управление может переходить с одного блока на другой. Тогда сложность определяется как
M = E − N + 2P,
где:
- M = цикломатическая сложность,
- E = количество ребер в графе,
- N = количество узлов в графе,
- P = количество компонент связности.
В другой формулировке используется граф, в котором каждая точка выхода соединена с точкой входа. В этом случае граф является сильносвязным, и цикломатическая сложность программы равна цикломатическому числу этого графа (также известному как первое число Бетти), которое определяется как
M = E − N + P.
Это определение может рассматриваться как вычисление числа линейно независимых циклов, которые существуют в графе, то есть тех циклов, которые не содержат в себе других циклов. Так как каждая точка выхода соединена с точкой входа, то существует по крайней мере один цикл для каждой точки выхода.
Для простой программы, или подпрограммы, или метода P всегда равно 1. Однако цикломатическая сложность может применяться к нескольким таким программам или подпрограммам (например, ко всем методам в классе), в таком случае P равно числу подпрограмм, о которых идет речь, так как каждая подпрограмма может быть представлена как независимая часть графа.
Может быть показано, что цикломатическая сложность любой структурированной программы с только одной точкой входа и одной точкой выхода эквивалентна числу точек ветвления (то есть, операторов if или условных циклов), содержащихся в этой программе, плюс один.
Цикломатическая сложность может быть распространена на программу с многочисленными точками выхода; в этом случае она равна
π − s + 2,
где:
- π - число точек ветвления в программе,
- s - число точек выхода.
Применение:
- Ограничение сложности при разработке: одно из первоначально предложенных Маккейбом применений состоит в том, что необходимо ограничивать сложность программ во время их разработки. Он рекомендует, чтобы программистов обязывали вычислять сложность разрабатываемых ими модулей и разделять модули на более мелкие всякий раз, когда цикломатическая сложность этих модулей превысит 10. Эта практика была включена НИСТ-ом в методику структурного тестирования с замечанием, что со времени исходной публикации Маккейба выбор значения 10 получил весомые подтверждения, однако в некоторых случаях может быть целесообразно ослабить ограничение и разрешить модули со сложностью до 15. В данной методике признается, что иногда могут существовать причины для выхода за рамки согласованного лимита. Это сформулировано как рекомендация: «Для каждого модуля следует либо ограничивать цикломатическую сложность до согласованных пределов, либо предоставить письменное объяснение того, почему лимит был превышен»;
- Применение при тестировании программного обеспечения: определение количества тестов, необходимых для полного покрытия кода. Цикломатическая сложность M имеет два свойства, для конкретного модуля:
- M - оценка сверху для количества тестов, обеспечивающих покрытие условий (точек ветвления);
- M - оценка снизу для количества маршрутов через граф потока управления и, таким образом, количества тестов для полного покрытия путей.
- В составе других метрик: используется в качестве одного из параметров в индексе удобства сопровождения (англ. maintainability index).
Dynamic - White box
Разработка тестов методом белого ящика (white-box test design technique): Процедура разработки или выбора тестовых сценариев на основании анализа внутренней структуры компонента или системы. (ISTQB)
Основанные на структуре методы проектирования тестирования используются для получения контрольных примеров из структурной характеристики, например структуры исходного кода или структуры меню. Если эти методы применяются к исходному коду приложения, то ожидаемые результаты для контрольных примеров получаются из базиса тестирования. Выбор, какие из основанных на структуре методов проектирования тестирования использовать в каждом конкретном случае, зависит от природы базиса тестирования и от присущих рисков. (ГОСТ 56920)
Поток данных (data flow): Абстрактное представление последовательности и возможных изменений состояния объектов данных, при котором состояние объекта это: создание, использование либо уничтожение. (Beizer)
Поток управления (control flow): Последовательность событий (путей) в процессе выполнения компонента или системы. (ISTQB)
Динамическое тестирование методом белого ящика - это стратегия, основанная на внутренних путях, структуре и реализации тестируемого программного обеспечения. Тесты здесь выполняются динамически, т.е. с запуском объекта тестирования и основаны на различных видах покрытии кода (путей исполнения программы).
Глобально основных техник динамического тестирования методом белого ящика всего две:
- Тестирование потока управления (Control Flow Testing);
- Тестирование потока данных (Data Flow Testing).
Фактически, это динамическая часть одного цельного тестирования, статическая часть которого - анализ и построение графа, описывается в предыдущей теме про статический анализ, а на этом определяется целевое покрытие (Coverage Target), создаются соответствующие тест-кейсы, тесты исполняются и результаты выполнения тестов анализируются.
Уровни тестового покрытия в тестировании потока управления (Control Flow Testing)
Под “покрытием" имеется в виду отношение объема кода, который уже был проверен, к объему, который осталось проверить. В тестировании потока управления покрытие определяется в виде нескольких различных уровней. Заметим, что эти уровни покрытия представлены не по порядку. Это потому, что в некоторых случаях проще определить более высокий уровень покрытия, а затем определить более низкий уровень покрытия в условиях высокого.
- 100% покрытие операторов (Statement/node coverage). Оператор (statement) - это сущность языка программирования, обычно являющаяся минимальным неделимым исполняемым блоком (ISTQB). Покрытие операторов - это метод проектирования тестов методом белого ящика, который включает в себя выполнение всех исполняемых операторов (if, for и switch) в исходном коде как минимум один раз. Процентное отношение операторов, исполняемых набором тестов, к их общему количеству является метрикой покрытия операторов. Борис Бейзер написал: "тестирование, меньшее чем это (100% покрытие операторов), для нового программного обеспечения является недобросовестным и должно быть признано преступлением. …”. Несмотря на то, что это может показаться разумной идеей, на таком уровне покрытия может быть пропущено много дефектов и затруднен анализ покрытия некоторых управляющих структур. Покрытие операторов позволяет найти:
- Неиспользованные выражения (Unused Statements);
- Мертвый код (Dead Code);
- Неиспользуемые ветви (Unused Branches);
- Недостающие операторы (Missing Statements);
- 100% покрытие альтернатив/ветвей (Decision/branch/all-edges/basis path/DC/C2/ decision-decision-path/edge coverage). «Решение» - это программная точка, в которой control flow имеет два или более альтернативных маршрута (ветви). На этом уровне достаточно такого набора тестов, в котором каждый узел с ветвлением (альтернатива), имеющий TRUE или FALSE на выходе, выполняется как минимум один раз, таким образом, для покрытия по веткам требуется как минимум два тестовых примера. На данном уровне не учитываются логические выражения, значения компонент которых получаются вызовом функций. В отличие от предыдущего уровня покрытия данный метод учитывает покрытие условных операторов с пустыми ветками. Покрытие альтернатив не гарантирует покрытие всех путей, но при этом гарантирует покрытие всех операторов;
Для более полного анализа компонент условий в логических операторах существуют следующие три метода, учитывающих структуру компонент условий и значения, которые они принимают при выполнении тестовых примеров.
100% покрытие условий (Condition/Toggle Coverage). Рассматриваются только выражения с логическими операндами, например, AND, OR, XOR. На этом уровне достаточно такого набора тест-кейсов, в котором каждое условие, имеющее TRUE и FALSE на выходе, выполнено как минимум один раз. Покрытие условий обеспечивает лучшую чувствительность к control flow, чем decision coverage. Для обеспечения полного покрытия по данному методу каждая компонента логического условия в результате выполнения тестовых примеров должна принимать все возможные значения, но при этом не требуется, чтобы само логическое условие принимало все возможные значения, т.е. Condition Coverage не дает гарантии полного decision coverage;
100% покрытие условий + альтернатив (Decision + Condition coverage). На этом уровне тест-кейсы создаются для каждого условия и для каждой альтернативы, т.е. данный метод сочетает требования предыдущих двух методов - для обеспечения полного покрытия необходимо, чтобы как логическое условие, так и каждая его компонента приняла все возможные значения;
100% покрытия множественный условий (Multiple condition coverage). Для выявления неверно заданных логических функций был предложен метод покрытия по всем условиям. При данном методе покрытия должны быть проверены все возможные наборы значений компонент логических условий: условий, альтернатив и условий/альтернатив. Т.е. в случае n компонент потребуется 2^n тестовых примеров, каждый из которых проверяет один набор значений. Тесты, необходимые для полного покрытия по данному методу, дают полную таблицу истинности для логического выражения. Несмотря на очевидную полноту системы тестов, обеспечивающей этот уровень покрытия, данный метод редко применяется на практике в связи с его сложностью и избыточностью. Еще одним недостатком метода является зависимость количества тестовых примеров от структуры логического выражения. Кроме того, покрытие множественных условий не гарантирует покрытие всех путей;
Покрытие бесконечного числа путей. Если, в случае зацикливания, количество путей становится бесконечным, то имеет смысл существенно их сократить, ограничив количество циклов выполнения, что позволит уменьшить количество тестовых случаев. Первый вариант - не выполнять цикл совсем; второй - выполнить цикл один раз; третий - выполнить цикл n раз, где n - это небольшое значение, представляющее символическое количество повторений цикла; четвертый - выполнить цикл m раз, где m - максимальное количество повторений цикла. Кроме того, можно выполнить цикл m-1 и m+1 раз. Перед тем, как начинать тестирование потока управления, должен быть выбран соответствующий уровень покрытия;
100% покрытие путей (Path coverage). Проверяет каждый линейно независимый путь в программе, что означает, что число тестовых примеров будет эквивалентно цикломатической сложности программы. Для кода модулей без циклов количество путей, как правило, достаточно мало, поэтому на самом деле можно построить тест-кейсы для каждого пути. Для модулей с циклами количество путей может быть огромным, что представляет неразрешимую проблему тестирования.
Путь на самом деле является направлением, потоком выполнения, который следует за последовательностью инструкций. Он охватывает функцию от входа до точки выхода. Он охватывает statement, branch/decision coverage. Покрытие пути можно понять в следующих терминах:
- Loop coverage: используется для проверки того, что все циклы были выполнены и сколько раз они были выполнены. Цель этого метода покрытия - убедиться, что циклы соответствуют предписанным условиям и не повторяются бесконечно и не завершаются ненормально. Цикл тестирования направлен на мониторинг от начала до конца цикла. Ценным аспектом этой метрики является определение того, выполняются ли циклы while и for более одного раза, т.к. эта информация не сообщается другими метриками;
- Function coverage: показывает, вызывали ли вы каждую функцию или процедуру;
- Call coverage: показывает, выполняли ли вы каждый вызов функции. Гипотеза состоит в том, что ошибки обычно возникают в интерфейсах между модулями (вызывающая функция и вызываемая функция). Также известен как покрытие пары вызовов (call pair coverage);
7 вышеперечисленных уровней описываются в книге Копленда “A Practitioner's Guide to Software Test Design”, но можно найти и другие
FSM coverage (Finite State Machine Coverage)
Конечные автоматы (FSM) имеют конечное число состояний, условий, которые приводят к внутренним переходам между состояниями, и соответствующее поведение ПО в каждом состоянии автомата. Автомат обычно моделирует поведение управляющей логики.
Покрытие FSM - покрытие конечного автомата, безусловно, является наиболее сложным методом покрытия кода. В этом методе покрытия вам нужно посмотреть, как много было переходов/посещений определенных по времени состояний (time-specific states). Оно также проверяет, сколько последовательностей включено в конечный автомат. Конечные автоматы могут иметь множество ветвей и несколько функциональных путей, а также любой скрытый путь (функциональный путь, пропущенный при проверке, или путь, непреднамеренно введенный на этапе реализации) в дизайне может вызвать серьезное нарушение функциональности, а также может создать тупик (система не может самостоятельно выйти из определенного состояния, даже если намеченный стимул присутствует).
Basis Path testing
Цель тестирования базового пути - в отличии от D-D Path (Decision-to-decision path) получить полное покрытие тех путей, которые находятся между точками принятия решений (decisions points) с высоким бизнес-риском и высокой бизнес-ценностью, т.к. проверять все возможные пути обходится слишком дорого. Это гибрид branch testing и path testing
LCSAJ coverage
LCSAJ (LCSAJ): Последовательность линейного кода с переходами, состоящая из трех элементов (условно определяемая номерами строк исходного кода):
- начало линейной последовательности выполняемых операторов
- конец линейной последовательности
- целевая строка кода, получающая управление после конца линейной последовательности
(ISTQB)
LCSAJ (linear code sequence and jump) «линейная последовательность кода и переход». Каждый LCSAJ представляет собой сегмент кода, который выполняется последовательно от начальной точки до конечной точки, а затем прерывает последовательный поток для передачи потока управления. Каждая строка кода имеет плотность (density), то есть количество раз, когда номер строки появляется в LCSAJ.
Один LCSAJ состоит из трех компонентов:
- Начало сегмента, который может быть ветвью или началом программы;
- Конец сегмента, который может быть концом ветви или концом программы;
- Конкретная целевая линия;
Его основное применение при динамическом анализе программного обеспечения, чтобы помочь ответить на вопрос «Сколько тестирования достаточно?». Динамический анализ программного обеспечения используются для измерения качества и эффективности тестовых данных программного обеспечения, где количественное определение выполняются в терминах структурных единиц кода при тестировании. В более узком смысле, LCSAJ является хорошо определенным линейным участком кода программы. При использовании в этом смысле, LCSAJ также называют JJ-путь (jump-to-jump path). 100% LCSAJ означает 100% Statement Coverage, 100% Branch Coverage, 100% procedure или Function call Coverage, 100% Multiple condition Coverage (в ISTQB говорится только о 100% Decision coverage).
Определенные метрики используются для проверки покрытия кода. Эти показатели могут помочь нам определить, достаточно ли тестирования или нет. Эти показатели называются коэффициентом эффективности тестирования (TER - Test Effectiveness Ratio):
- TER-1: количество операторов, выполненных с помощью тестовых данных, деленное на общее количество операторов;
- TER-2: количество ветвей потока управления, выполненных тестовыми данными, деленное на общее количество ветвей потока управления;
- TER-3: количество LCSAJ, выполненных тестовыми данными, деленное на общее количество LCSAJ;
Исследователи ссылаются на коэффициент покрытия путей длиной n LCSAJ как на коэффициент эффективности теста (TER) n + 2.
Data Flow Testing
Тестирование потока данных - это еще один набор методов / стратегий белого ящика, который связан с анализом потока управления, но с точки зрения жизненного цикла переменной. Переменные определяются, используются и уничтожаются, когда в них больше нет необходимости. Аномалии в этом процессе, такие как использование переменной без ее определения или после ее уничтожения, могут привести к ошибке. Рапс и Вьюкер, популяризаторы данного метода, писали: "Мы уверены, что, как нельзя чувствовать себя уверенным в программе без выполнения каждого ее оператора в рамках какого-то тестирования, так же не следует быть уверенным в программе без видения результатов использования значений, полученных от любого и каждого из вычислений".
Когда «поток данных» через информационную систему представлен графически, он известен как диаграмма потока данных (Data Flow Diagram). Она также используется для визуализации обработки данных. Но не нужно путать это с графом потока данных (Data Flow Graph), который используется в Data Flow Testing. Граф потока данных похож на граф потока управления тем, что показывает поток обработки через модуль. Дополнительно к этому, он детализирует определение, использование и уничтожение каждой из переменных модуля. Мы построим эти диаграммы и убедимся, что шаблоны определение-использование-уничтожение являются подходящими. Сначала мы проведем статический анализ. Под "статическим" мы имеем в виду, что мы исследуем диаграмму (формально через проверки или неформально беглыми просмотрами). Потом мы проведем динамические тесты модуля. Под "динамическими" мы понимаем, что мы создаем и исполняем тестовые сценарии.
Так как тестирование потока данных основано на потоке управления модуля, то, предположительно, поток управления в основном верный. Процесс тестирования потока данных сводится к выбору достаточного количества тестов, таких как:
- каждое "определение" прослеживается для каждого его "использования";
- каждое "использование" прослеживается из соответствующего ему "определения";
Чтобы сделать это, перечислим маршруты в модуле. Порядок выполнения такой же, как и в случае с тестированием потока управления: начинаем с точки входа в модуль, строим самый левый маршрут через весь модуль и заканчиваем на выходе из него. Возвращаемся в начало и идём по другому направлению в первом разветвлении. Прокладываем этот путь до конца. Возвращаемся в начало и идём по другому направлению во втором разветвлении, потом в третьем и т.д., пока не пройдем все возможные пути. Затем создадим хотя бы один тест для каждой переменной, чтобы покрыть каждую пару определение-использование.
Существуют условные обозначения, которые могут помочь в описании последовательных во времени пар в жизненном цикле переменной:
- ~ - переменная еще не существует или предыдущий этап был последним
- d - определено, создано, инициализировано
- k - не определено, убито
- u - используется (c - использование вычислений; p - использование предикатов)
Таким образом, ~ d, du, kd, ud, uk, uu, k ~, u ~ являются вполне допустимыми комбинациями, когда ~ u, ~ k, dd, dk, kk, ku, d ~ являются аномалиями, потенциальными или явными ошибками. В настоящее время практически все они эффективно обнаруживаются компиляторами или, по крайней мере, IDE, и нам редко требуется выполнять статический анализ для обнаружения этих аномалий. То же самое относится и к динамическому анализу, который сфокусирован на исследовании / выполнении du пар - современные языки программирования снижают вероятность возникновения проблем, связанных с du. Так что в настоящее время такая проверка в основном не стоит усилий.
Dynamic - Black box
Разработка тестов методом черного ящика (black box test design technique): Процедура создания и/или выбора тестовых сценариев, основанная на анализе функциональной или нефункциональной спецификации компонента или системы без знания внутренней структуры. (ISTQB)
Основанные на спецификации методы проектирования тестирования используются для получения контрольных примеров из базиса тестирования, определяющего ожидаемое поведение элемента тестирования. При использовании этих методов входные данные для тестирования контрольного примера и ожидаемый результат получаются из базиса тестирования. Выбор, какие из основанных на спецификации методов проектирования тестирования использовать в каждой конкретной ситуации, зависит от природы базиса тестирования и/или элемента тестирования, и от присущих рисков. (ГОСТ 56920)
Все specification-based или Black Box testing techniques могут быть удобно описаны и систематизированы с помощью следующей таблицы:
| Группа | Техника | Когда используется |
|---|---|---|
Элементарные техники:
| Equivalence Partitioning | Входные и выходные параметры имеют большое количество возможных значений |
| Boundary Value Analysis | Значения параметров имеют явные (например, четко определенные в документации) границы и диапазоны или неявные (например, известные технические ограничения) границы | |
Комбинаторные стратегии:
| All Combinations | Количество возможных комбинаций входных значений достаточно мало, или каждая отдельная комбинация входных значений приводит к определенному выходному значению |
| Pairwise Testing | Количество входных комбинаций чрезвычайно велико и должно быть сокращено до приемлемого набора кейсов | |
| Each Choice Testing | У вас есть функции, при которых скорее конкретное значение параметра вызывает ошибку, нежели комбинация значений | |
| Base Choice Testing | Вы можете выделить набор значений параметров, который имеет наибольшую вероятность использования | |
Продвинутые техники:
| Decision Table Testing | Существует набор комбинаций параметров и их выходных данных, описываемых бизнес-логикой или другими правилами |
| Classification Tree Method | У вас есть иерархически структурированные данные, или данные могут быть представлены в виде иерархического дерева | |
| State Transition Testing | В функциональности есть очевидные состояния, переходы которых регулируются правилами (например, потоки) | |
| Cause-Effect Graphing | Причины (входы) и следствия (выходы) связаны большим количеством сложных логических зависимостей | |
| Scenario Testing | В функционале есть четкие сценарии | |
| Другие техники | Random Testing | Вам необходимо имитировать непредсказуемость реальных вводных данных, или функциональность имеет несистематические дефекты |
| Syntax Testing | Функциональность имеет сложный синтаксический формат для входных данных (например, коды, сложные имена электронной почты и т. д.) |
Эквивалентное разделение (Equivalence Partitioning (ISTQB/Myers 1979) / Equivalence Class Testing (Lee Copeland))
Класс эквивалентности представляет собой набор данных, которые либо одинаково обрабатываются модулем, либо их обработка выдает одинаковые результаты. При тестировании любое значение данных, входящее в класс эквивалентности, аналогично любому иному значению класса.
Эквивалентное разделение - это разделение всего набора данных ввода / вывода на такие разделы. Таким образом, вам не нужно выполнять тесты для каждого элемента подмножества, и достаточно одной проверки, чтобы охватить все подмножество. Хитрость заключается в том, чтобы увидеть и идентифицировать разделы, т.к. далеко не всегда они представляют собой числа.
Пример: Мы пишем модуль для системы отдела кадров, который определяет, в каком порядке нужно рассматривать заявления о приеме на работу в зависимости от возраста кандидата.
Правила нашей организации таковы:
- от 0 до 16 - не принимаются;
- от 16 до 18 - могут быть приняты только на неполный рабочий день;
- от 18 до 55 - могут быть приняты как сотрудники на полный рабочий день;
- от 55 до 99 - не принимаются;
Что в коде выглядит как:
- If (applicantAge >= 0 && applicantAge <=16)
- hireStatus="NO";
- If (applicantAge >= 16 && applicantAge <=18)
- hireStatus="PART";
- If (applicantAge >= 18 && applicantAge <=55)
- hireStatus="FULL";
- If (applicantAge >= 55 && applicantAge <=90)
- hireStatus="NO";
Из чего очевидно, что вместо 100 кейсов нам понадобится 4 по числу эквивалентных классов, все остальные кейсы внутри своих классов будут давать одинаковый результат тестов и являются избыточными.
Теперь мы готовы начать тестирование? Вероятно, нет. Что насчет таких входных данных как 969, -42, FRED или &$#! ? Должны ли мы создавать тестовые сценарии для некорректных входных данных? Для того, чтобы понять ответ, мы должны проверить подход, который пришел из объектно-ориентированного мира, названный "проектирование-по-контракту".
В подходе "проектирование-по-контракту" модули (в парадигме объектно-ориентированного программирования они называются "методами", но "модуль" является более общим термином) определены в терминах предусловий и постусловий. Постусловия определяют, что модуль обещает сделать (вычислить значение, открыть файл, напечатать отчет, обновить запись в базе данных, изменить состояние системы и т.д.). Предусловия описывают требования к модулю, при которых он переходит в состояние, описываемое постусловиями.
Например, если у нас есть модуль "openFile", что он обещает сделать? Открыть файл. Какие будут разумные предусловия для этого модуля?
- файл должен существовать,
- мы должны предоставить имя (или другую идентифицирующую информацию),
- файл должен быть "открываемым", т.е. он не может быть открытым в другом процессе,
- у нас должны быть права доступа к файлу и т.д.
Предусловия и постусловия основывают контракт между модулем и всеми, кто его вызывает. Тестирование-по-контракту основывается на философии проектирования-по-контракту. При использовании данного подхода мы создаем только те тест-кейсы, которые удовлетворяют нашим предусловиям. Например, мы не будем тестировать модуль "openFile", если файл не существует. Причина проста. Если файл не существует, то openFile не обещает работать. Если не существует требования работоспособности в определенных условиях, то нет необходимости проводить тестирование в этих условиях.
В этот момент тестировщики обычно возражают. Да, они согласны, что модуль не претендует на работу в этом случае, но что делать, если предусловия нарушаются в процессе разработки? Что делать системе? Должны ли мы получить сообщение об ошибке на экране или дымящуюся воронку на месте нашей компании? Другим подходом к проектированию является оборонительное проектирование. В этом случае модуль предназначен для приема любого входного значения. Если выполнены обычные предусловия, то модуль достигнет своих обычных постусловий. Если обычные предварительные условия не выполняются, то модуль сообщит вызывающему, возвратив код ошибки или бросив исключение (в зависимости от используемого языка программирования). На самом деле, это уведомление является еще одним из постусловий модуля.
На основе этого подхода мы могли бы определить оборонительное тестирование: подход, который анализирует как обычные, так и необычные предварительные условия.
Нужно ли нам делать проверку с такими входными значениями, как -42, FRED и &$#! @? Если мы используем проектирование-по-контракту и тестирование-по-контракту, то ответ "Нет". Если мы используем оборонительное проектирование и, поэтому, оборонительное тестирование, то ответ "Да". Спросите ваших проектировщиков, какой подход они используют. Если их ответом будет «контрактный» либо «оборонительный», то вы знаете, какой стиль тестирования использовать. Если они ответят "Хм?", то это значит, что они не думают о том, как взаимодействуют модули. Они не думают о предусловиях и постусловиях контрактов. Вам стоит ожидать, что интеграционное тестирование будет главным источником дефектов, будет более сложным и потребует больше времени, чем ожидалось.
Несмотря на то, что тестирование классов эквивалентности полезно, его величайшим вкладом является то, что оно приводит нас к тестированию граничных значений.
Анализ граничных значений (BVA - Boundary Value Analysis (Myers 1979)/range checking)
Тестирование классов эквивалентности - это самая основная методика тест-дизайна. Она помогает тестировщикам выбрать небольшое подмножество из всех возможных тестовых сценариев и при этом обеспечить приемлемое покрытие. У этой техники есть еще один плюс. Она приводит к идее о тестировании граничных значений - второй ключевой технике тест-дизайна.
Пример. Выше описывались правила, которые указывали, каким образом будет происходить обработка заявок на вакансии в зависимости от возраста соискателя.
Обратите внимание на проблемы на границах - это "края" каждого класса. Возраст "16" входит в два различных класса эквивалентности (как и "18", и "55"). Первое правило гласит не нанимать шестнадцатилетних. Второе правило гласит, что шестнадцатилетние могут быть наняты на неполный рабочий день Тестирование граничных значений фокусируется на границах именно потому, что там спрятано очень много дефектов. Опытные тестировщики сталкивались с этой ситуацией много раз. У неопытных тестировщиков может появиться интуитивное ощущение, что ошибки будут возникать чаще всего на границах. Эти дефекты могут быть в требованиях, или в коде, если программист ошибется с указанием границ в коде (включительно/не включительно, индекс +-1).
Попробуем исправить приведенный выше пример:
- от 0 до 15 - не принимаются;
- от 16 до 17 - могут быть приняты только на неполный рабочий день;
- от 18 до 54 - могут быть приняты как сотрудники на полный рабочий день;
- от 55 до 99 - не принимаются;
А что насчет возраста -3 и 101? Обратите внимание, что требования не указывают, как должны быть рассмотрены эти значения. Мы можем догадаться, но "угадывание требований" не является приемлемой практикой. Следующий код реализует исправленные правила:
- if (applicantAge >= 0 && applicantAge <= 15)
- hireStatus = "NO";
- if (applicantAge >= 16 && applicantAge <= 17)
- hireStatus = "PART";
- if (applicantAge >= 18 && applicantAge <= 54)
- hireStatus = "FULL";
- if (applicantAge >= 55 && applicantAge <= 99)
- hireStatus = "NO";
В этом примере интересными значениями на границах или вблизи них являются {-1, 0, 1}, {15, 16, 17}, {17, 18, 19}, {54, 55, 56} и {98, 99, 100}. Другие значения, например {-42, 1001, FRED, %$#@} могут быть включены в зависимости от предусловий документации модуля.
Для создания тест-кейсов для каждого граничного значения определите классы эквивалентности, выберите одну точку на границе, одну точку чуть ниже границы и одну точку чуть выше границы. Стоит отметить, что точка чуть выше границы может входить в другой класс эквивалентности. В таком случае не нужно дублировать тест. То же самое может быть верно по отношению точки чуть ниже границы.
Тестирование граничных значений является наиболее подходящим там, где входные данные являются непрерывным диапазоном значений.
Тестирование таблиц решений (Decision Table testing)
Этот простой, но эффективный метод заключается в документировании бизнес-логики в таблице как наборы правил, условий выполнения действий и самих действий. Тестирование таблиц принятия решений может быть использовано, когда система должна реализовывать сложные бизнес-правила, когда эти правила могут быть представлены в виде комбинации условий и когда эти условия имеют дискретные действия, связанные с ними.
Пример. Компания по автострахованию дает скидку водителям, которые состоят в браке и/или хорошо учатся.
| - | Правило 1 | Правило 2 | Правило 3 | Правило 4 |
|---|---|---|---|---|
| Условия | - | - | - | - |
| Состоит в браке? | Да | Да | Нет | Нет |
| Хороший студент? | Да | Нет | Да | Нет |
| - | - | - | - | - |
| Действия | - | - | - | - |
| Скидка ($) | 60 | 25 | 50 | 0 |
эта таблица содержит все комбинации условий. Задав два бинарных условия ("да" или "нет"), возможные комбинации будут: ("да", "да"), ("да", "нет"), ("нет", "да") и ("нет", "нет"). Каждое правило представляет собой одну из этих комбинаций. Нам, тестировщикам, нужно будет проверить, что определяются все комбинации условий. Пропущенное сочетание может привести к разработке такой системы, которая не сможет правильно обработать определенный набор исходных данных. Каждое правило является причиной "запуска" действия. Каждое правило может задать действие, уникальное для этого правила, или правила могут иметь общие действия. Для каждого правила с помощью таблицы решений можно указать более одного действия. Опять же, эти правила могут быть уникальными или быть общими. В такой ситуации выбрать тесты просто - каждое правило (вертикальная колонка) становится тест-кейсом. Условия указывают на входные значения, а действия - на ожидаемые результаты.
Если тестируемая система имеет сложные бизнес-правила, а у ваших бизнес-аналитиков или проектировщиков нет документации этих правил, то тестировщикам следует собрать эту информацию и представить ее в виде таблицы решений. Причина проста: представляя поведение системы в такой полной и компактной форме, тест-кейсы могут быть созданы непосредственно из таблицы решений. При тестировании для каждого правила создается как минимум один тест-кейс. Если состояния этого правила бинарные, то должно быть достаточно одного теста для каждого сочетания. С другой стороны, если состояние является диапазоном значений, то тестирование должно учитывать и нижнюю, и высшую границы диапазона. Таким образом мы объединяем идею тестирования граничных значений с тестированием таблиц решений.
Чтобы создать тестовую таблицу, просто измените заголовки строк и столбцов: правила станут тест-кейсами, условия входными значениями, а действия ожидаемыми результатами.
Комбинаторные техники тест-дизайна (Combination Strategies)
Комбинаторное тестирование (combinatorial testing): Метод, позволяющий выделить подходящую подгруппу тестовых комбинаций с целью добиться предопределенного уровня покрытия при тестировании объекта с множественными параметрами в случаях, когда эти параметры сами по себе состоят из нескольких значений, что приводит к появлению большего числа комбинаций, чем можно успеть протестировать за отведенное время. См. также метод дерева классификации, попарное тестирование, n-мерное (переборное) тестирование, тестирование с использованием ортогонального массива. (ISTQB)
Тестовые примеры выбираются на основе некоторого понятия покрытия, и цель стратегии комбинирования состоит в том, чтобы выбрать тестовые примеры из набора тестов таким образом, чтобы было достигнуто 100% покрытие.
- 1-wise coverage (each-used) - это самый простой критерий покрытия. Для 100% each-used покрытия требуется, чтобы каждое значение каждого параметра было включено хотя бы в один тестовый пример в наборе тестов.
- 2-wise (pair-wise) coverage требует, чтобы каждая возможная пара значений любых двух параметров была включена в некоторый тестовый пример. Обратите внимание, что один и тот же тестовый пример часто охватывает более одной уникальной пары значений.
- Естественным продолжением 2-wise coverage является t-wise coverage, которое требует включения всех возможных комбинаций интересных значений параметров t в какой-либо тестовый пример в наборе тестов.
- Самый тщательный критерий покрытия, N-wise coverage, требует набора тестов, который содержит все возможные комбинации значений параметров в input parameter model (IPM).
Все комбинации (All combinations): как видно из названия, этот алгоритм подразумевает генерацию всех возможных комбинаций. Это означает исчерпывающее тестирование и имеет смысл только при разумном количестве комбинаций. Например, 3 переменные с 3 значениями для каждой дают нам матрицу параметров 3х3 с 27 возможными комбинациями.
Тестирование каждого выбора (EC - Each choice testing): эта стратегия требует, чтобы каждое значение каждого параметра было включено по крайней мере в один тестовый пример (Ammann & Offutt, 1994). Это также определение 1-wise coverage.
Тестирование базового выбора (BC - Base choice testing): алгоритм стратегии комбинирования базового выбора начинается с определения одного базового тестового примера. Базовый тестовый пример может быть определен по любому критерию, включая простейший, наименьший или первый. Критерий, предложенный Амманном и Оффуттом (Ammann & Offutt, 1994), - это «наиболее вероятное значение» с точки зрения конечного пользователя. Это значение может быть определено тестировщиком или основано на рабочем профиле, если таковой существует. Из базового тестового примера создаются новые тестовые примеры, изменяя интересующие значения одного параметра за раз, сохраняя значения других параметров фиксированными в базовом тестовом примере. Базовый выбор включает каждое значение каждого параметра по крайней мере в одном тестовом примере, поэтому он удовлетворяет 1-wise coverage.
Попарное тестирование** (Pairwise testing)
Pairwise testing - техника тест-дизайна, а именно метод обнаружения дефектов с использованием комбинационного метода из двух тестовых случаев. Он основан на наблюдениях о том, что большинство дефектов вызвано взаимодействием не более двух факторов (дефекты, которые возникают при взаимодействии трех и более факторов, как правило менее критичны). Следовательно, выбирается пара двух тестовых параметров, и все возможные пары этих двух параметров отправляются в качестве входных параметров для тестирования. Pairwise testing сокращает общее количество тест-кейсов, тем самым уменьшая время и расходы, затраченные на тестирование. Захватывающей надеждой попарного тестирования является то, что путем создания и запуска 1-20% тестов вы найдете 70-85% от общего объема дефектов.
Пример: По ТЗ сайт должен работать в 8 браузерах, используя различные плагины, запускаться на различных клиентских операционных системах, получать страницы от разных веб-серверов, работать с различными серверными, операционными системами. Итого:
- 8 браузеров;
- 3 плагина;
- 6 клиентских операционных систем;
- 3 сервера;
- 3 серверных операционных системы;
\= 1296 комбинаций. Количество комбинаций настолько велико, что, скорее всего, у нас не хватит ресурсов, чтобы спроектировать и пройти тест-кейсы. Не следует пытаться проверить все комбинации значений для всех переменных, а нужно проверять комбинации пар значений переменных.
Использование всех пар для создания тест-кейсов основывается на двух техниках:
- ортогональные массивы (OA - Orthogonal Array): это двумерный массив символов. На примере выше мы составляем таблицу, где столбцы представляют собой переменные (браузер, плагин, клиентская операционная система, веб-сервер и серверная операционная система, а строки - значения каждой переменной (Chrome/Opera, Windows 8/10/11 и т.п.). После чего нужно определить ортогональный массив, у которого будет столбец для каждой переменной (каждый столбец ортогонального массива имеет столько же вариантов значений, сколько имеет ваша переменная). Используя ортогональный массив для примера выше, все пары всех значений всех переменных могут быть покрыты всего лишь 64-мя тестами.
- алгоритм Allpairs: генерирует пары непосредственно, не прибегая к таким к ортогональным массивам. "Несбалансированный" характер алгоритма выбора всех пар требует только 48 тестов для примера. Следует отметить, что комбинации, выбранные методом ортогонального массива, могут быть не такими же, как те, которые выбраны Allpairs. Но это не важно. Важно лишь то, чтобы были выбраны все парные комбинации параметров. Это будут комбинации, которые мы хотим проверить.
Подробнее с разбором примера см. у Копленда в главе 6.
На практике же вручную эти массивы никто не формирует, всю механику реализуют автоматизированные инструменты, самый популярный из них PICT. Тестировщику остается лишь подготовить и скормить данные.
Classification tree method
Метод дерева классификации (classification tree method): Разработка тестов методом черного ящика, в которой тестовые сценарии, описанные средствами дерева классификации, разрабатываются для проверки комбинаций выборок входных и/или выходных подмножеств. (Grochtmann) См. также комбинаторное тестирование.
Дерево классификации (Classification tree): структура, показывающее иерархически упорядоченные классы эквивалентности, которое используется для разработки тестовых примеров в методе дерева классификации (Classification tree method). Не путать с Decision tree.
Метод дерева классификации: вид комбинаторной техники, в которой тестовые примеры, описанные с помощью дерева классификации, предназначены для выполнения комбинаций представителей входных и / или выходных доменов.

Чтобы рассчитать количество тестовых примеров, нам необходимо проанализировать требования, определить соответствующие тестовые функции (классификации) и их соответствующие значения (классы).
Обычно для создания Classification tree используется инструмент Classification Tree Editor. Если же взять лист бумаги и ручку, то у нас есть тестовый объект (целое приложение, определенная функция, абстрактная идея и т. д.) вверху как корень. Мы рисуем ответвления от корня как классификации (проверяем соответствующие аспекты, которые мы определили). Затем, используя классы эквивалентности и анализ граничных значений, мы определяем наши листья как классы из диапазона всех возможных значений для конкретной классификации. И если некоторые из классов могут быть классифицированы далее, мы рисуем под-ветку / классификацию с собственными листьями / классами. Когда наше дерево завершено, мы делаем проекции листьев на горизонтальной линии (Test case), используя одну из комбинаторных стратегий (all combinations, each choice и т. д.), и создаем все необходимые комбинации.
Максимальное количество тестовых примеров - это декартово произведение всех классов всех классификаций в дереве, быстро приводящее к большим числам для реалистичных тестовых задач. Минимальное количество тестовых примеров - это количество классов в классификации с наиболее содержащимися классами. На втором этапе тестовые примеры составляются путем выбора ровно одного класса из каждой классификации дерева классификации.
Тестирование переходов между состояниями (State Transition testing)
Таблица состояний (state table): Таблица, показывающая конечные переходы для каждого состояния вследствие каждого возможного события, как для корректных, так и для некорректных переходов. (ISTQB)
Тестирование переходов между состояниями определяется как метод тестирования ПО, при котором изменения входных условий вызывают изменения состояния в тестируемом приложении (AUT). В этом методе тестировщик предоставляет как положительные, так и негативные входные значения теста и записывает поведение системы. Это модель, на которой основаны система и тесты. Любая система, в которой вы получаете разные выходные данные для одного и того же ввода, в зависимости от того, что произошло раньше, является системой конечных состояний. Техника тестирования переходов между состояниями полезна, когда вам нужно протестировать различные системные переходы. Этот подход лучше всего подходит там, где есть возможность рассматривать всю систему как конечный автомат. Для наглядности возьмем классический пример покупки авиабилетов:
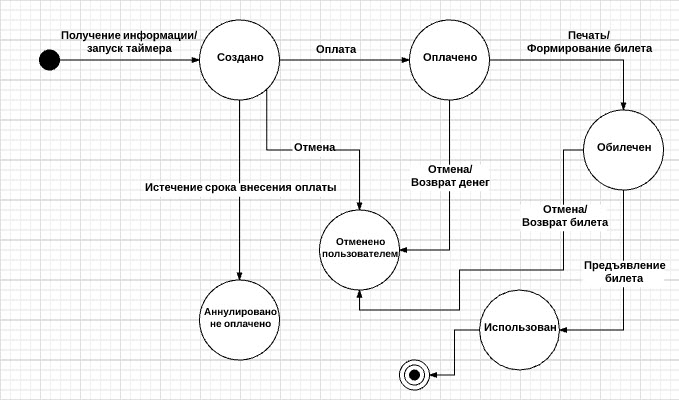
- Состояние (state, представленное в виде круга на диаграмме) - это состояние приложения, в котором оно ожидает одно или более событий. Состояние помнит входные данные, полученные до этого, и показывает, как приложение будет реагировать на полученные события. События могут вызывать смену состояния и/или инициировать действия;
- Переход (transition, представлено в виде стрелки на диаграмме) - это преобразование одного состояния в другое, происходящее по событию;
- Событие (event, представленное ярлыком над стрелкой) - это что-то, что заставляет приложение поменять свое состояние. События могут поступать извне приложения, через интерфейс самого приложения. Само приложение также может генерировать события (например, событие «истек таймер»). Когда происходит событие, приложение может поменять (или не поменять) состояние и выполнить (или не выполнить) действие. События могут иметь параметры (например, событие «Оплата» может иметь параметры «Наличные деньги», «Чек», «Приходная карта» или «Кредитная карта»);
- Действие (action, представлено после «/» в ярлыке над переходом) инициируется сменой состояния («напечатать билет», «показать на экране» и др.). Обычно действия создают что-то, что является выходными/возвращаемыми данными системы. Действия возникают при переходах, сами по себе состояния пассивны;
- Точка входа обозначается черным кружком;
- Точка выхода показывается на диаграмме в виде мишени;
Все начинается с точки входа. Мы (клиенты) предоставляем авиакомпании информацию для бронирования. Служащий авиакомпании является интерфейсом между нами и системой бронирования авиабилетов. Он использует предоставленную нами информацию для создания бронирования. После этого наше бронирование находится в состоянии «Создано». После создания бронирования система также запускает таймер. Если время таймера истекает, а забронированный билет еще не оплачен, то система автоматически снимает бронь.
Каждое действие, выполненное над билетом, и соответствующее состояние (отмена бронирования пользователем, оплата билета, получение билета на руки, и т. д.) отображаются в блок-схеме.
На основании полученной схемы составляется набор тестов.
Определим четыре разных уровня покрытия:
- Набор тестов, в котором все состояния будут посещены как минимум один раз. Этому требованию удовлетворяет набор из трех тестов, показанный ниже. Обычно это низкий уровень тестового покрытия.
- Набор тестов, в котором все события выполнятся как минимум один раз. Следует отметить, что тест-кейсы, которые покрывают каждое событие, могут быть точно теми же, которые покрывают каждое состояние. Опять же, это низкий уровень покрытия.
- Набор тестов, в котором все пути будут пройдены как минимум один раз. Несмотря на то, что этот уровень является наиболее предпочтительным из-за его уровня покрытия, это может быть неосуществимо. Если диаграмма состояний и переходов содержит петли, то количество возможных путей может быть бесконечным.
- Набор тестов, в котором все переходы будут осуществлены как минимум один раз. Этот уровень тестирования обеспечивает хороший уровень покрытия без порождения большого количества тестов. Этот уровень, как правило, один из рекомендованных.
Диаграмма состояний и переходов - не единственный способ документирования поведения системы. Диаграммы, возможно, легче в понимании, но таблицы состояний и переходов могут быть проще в использовании на постоянной и временной основе. Таблицы состояний и переходов состоят из четырех столбцов - "Текущее состояние", "Событие", "Действие" и "Следующее состояние". Преимущество таблицы состояний и переходов в том, что в ней перечисляются все возможные комбинации состояний и переходов, а не только допустимые. При крайне необходимом тестировании систем с высокой степенью риска, например авиационной радиоэлектротехники или медицинских устройств, может потребоваться тестирование каждой пары состояние-переход, включая те, которые не являются допустимыми. Кроме того, создание таблицы состояний и переходов часто извлекает комбинации, которые не были определены, задокументированы или рассмотрены в требованиях. Очень полезно обнаружить эти дефекты до начала кодирования.
Использование таблицы состояний и переходов может помочь обнаружить дефекты в реализации, которые позволяют недопустимые пути из одного состояния в другое. Недостатком таких таблиц является то, что, когда количество состояний и событий возрастает, они очень быстро становятся огромными. Кроме того, в таблицах, как правило, большинство клеток пустые.
Подробнее с разбором примера см. у Копленда в главе 7.
Domain testing
Анализ доменов (domain analysis): Методика разработки тестов, относящаяся к методу черного ящика, использующаяся для определения действенных и эффективных тестовых сценариев в случаях, когда множественные параметры могут или должны быть протестированы одновременно. Методика базируется и обобщает методы эквивалентного разбиения и анализа граничных значений/ (ISTQB)
В главах по тестированию классов эквивалентности и граничных значений мы рассмотрели тестирование одиночных переменных, которые требовали оценки в указанных диапазонах. В этой главе мы рассмотрим тестирование нескольких переменных одновременно. Существуют две причины, по которым стоит обратить на это внимание:
- у нас редко будет достаточно времени на создание тест-кейсов для каждой переменной в нашей системе. Их просто слишком много;
- часто переменные взаимодействуют. Значение одной переменной ограничивает допустимые значения другой. В этом случае, если проверять переменные поодиночке, можно не обнаружить некоторые дефекты;
Domain-тестирование - это техника, которая может применяться для определения эффективных и действенных тест-кейсов, когда несколько переменных (например, поля ввода) должны проверяться вместе - либо для эффективности, либо по причине их логического взаимодействия. Она использует и обобщает тестирование классов эквивалентности и граничных значений в n одномерных измерениях. Подобно этим техникам, мы ищем случаи, где граница была неверно определена или реализована. Несмотря на то, что эта техника лучше всего подходит для числовых значений, она может быть обобщена и на другие типы - boolean, string, enumeration и т.д.
В двухмерном измерении (с двумя взаимодействующими параметрами) могут возникнуть следующие дефекты:
- сдвиг границы - граница, перемещённая вертикально или горизонтально;
- направление границы - граница, повёрнутая под неправильным углом;
- пропущенная граница;
- лишняя граница

Подробнее с разбором примера см. у Копленда в главе 8.
Use case-based Testing
Сценарий использования системы (use case): Последовательность операций во взаимодействии актера и компонента или системы со значимым результатом, при которой актером может быть как пользователь, так и все, что может обмениваться информацией с системой. (ISTQB)
До сих пор мы исследовали техники разработки тестовых сценариев для частей системы - входные переменные с их диапазонами и границами, бизнес-правила, представленные в виде таблиц решений, а также поведения системы, представленные с помощью диаграмм состояний и переходов. Теперь пришло время рассмотреть тестовые сценарии, которые используют системные функции с начала и до конца путем тестирования каждой из их индивидуальных операций.
Сегодня самым популярным подходом определения выполняемых системой операций является диаграмма вариантов использования (диаграмма прецедентов, Use case diagram). Как и таблицы решений и диаграммы состояний и переходов, диаграммы вариантов использования обычно создаются разработчиками для разработчиков. Но, как и другие техники, диаграммы вариантов использования содержат много полезной информации и для тестировщиков. Варианты использования были созданы Иваром Якобсоном и объяснены в его книге "Объектно-ориентированная разработка программ: подход, основанный на вариантах использования". Якобсон определил
Вариант использования (Use Case) - это сценарий, который описывает использование системы действующим лицом для достижения определенной цели (Ивар Якобсон - "Объектно-ориентированная разработка программ: подход, основанный на вариантах использования").
- Действующее лицо (или актер) - это пользователь, играющий роль с уважением к системе, старающегося использовать систему для достижения чего-то важного внутри конкретного контекста. Действующими лицами в основном являются люди, хотя действующими лицами также могут выступать другие системы;
- "Сценарий" - это последовательность шагов, которые описывают взаимодействия между актером и системой. Заметьте, что варианты использования определены с точки зрения пользователя, а не системы. Заметьте также, что операции, выполняемые внутри системы, хоть и важны, но не являются частью определения вариантов использования. Набор вариантов использования составляет функциональные требования системы.
Прежде чем использовать сценарии для создания Test case, их необходимо подробно описать с помощью шаблона. Шаблоны могут варьироваться от проекта к проекту. Но среди таких обычных полей, как имя, цель, предварительные условия, актер (ы) и т. д., всегда есть основной успешный сценарий и так называемые расширения (плюс иногда подвариации). Расширения - это условия, которые влияют на основной сценарий успеха. А подвариации - это условия, которые не влияют на основной flow, но все же должны быть рассмотрены. После того, как шаблон заполнен данными, мы создаем конкретные Test case, используя методы эквивалентного разделения и граничных значений. Для минимального охвата нам нужен как минимум один тестовый сценарий для основного сценария успеха и как минимум один Test case для каждого расширения. Опять же, этот метод соответствует общей формуле «получите условия, которые меняют наш результат, и проверьте комбинации». Но способ получить это - проанализировать поведение Системы с помощью сценариев.
Польза вариантов использования в том, что они:
- позволяют выявить функциональные требования системы с точки зрения пользователя несмотря на техническую перспективу и независимо от того, какая парадигма разработки использовалась;
- могут быть использованы для активного вовлечения пользователей в процесс сбора требований и определений;
- предоставляют базис для идентификации ключевых компонентов системы, структур, баз данных и связей;
- служат основанием для разработки тест-кейсов системы на приемочном уровне.
Подробнее с разбором примера см. у Копленда в главе 8.
Как создать хорошие сценарии (Сэм Канер):
- Напишите истории жизни для объектов в системе.
- Перечислите возможных пользователей, проанализируйте их интересы и цели.
- Подумайте об отрицательных пользователях: как они хотят злоупотреблять вашей системой?
- Перечислите «системные события». Как система справляется с ними?
- Перечислите «особые события». Какие приспособления система делает для них?
- Перечислите преимущества и создайте сквозные задачи, чтобы проверить их.
- Интервью пользователей об известных проблемах и сбоях старой системы.
- Работайте вместе с пользователями, чтобы увидеть, как они работают и что они делают.
- Читайте о том, что должны делать подобные системы.
- Изучите жалобы на предшественника этой системы или ее конкурентов.
- Создать фиктивный бизнес. Относитесь к нему как к реальному и обрабатывайте его данные.
- Попробуйте преобразовать реальные данные из конкурирующего или предшествующего приложения.
Cause/Effect, Cause-Effect (CE)
Таблица причинно-следственных решений (cause-effect decision table): См. таблица решений.
Таблица решений (decision table): Таблица, отражающая комбинации входных данных и/или причин с соответствующими выходными данными и/или действиям (следствиям), которая может быть использована для проектирования тестовых сценариев. (ISTQB)
Тестовые примеры должны быть разработаны так, чтобы проявлять принципы, которые характеризуют взаимосвязь между входными и выходными данными компонента, где каждый принцип соответствует единственной возможной комбинации входных данных компонента, которые были выражены как логические значения. Для каждого тестового примера следует уточнить:
- Логическое состояние для каждого эффекта;
- Логическое состояние (истина или ложь) по любой причине;
Граф причинно-следственных связей (Cause-Effect Graph) использует такую модель логических взаимосвязей между причинами и следствиями для компонента. Каждая причина выражается как условие, которое может быть истинным, ложным на входе или комбинацией входных данных компонента. Каждый эффект выражается в виде логического выражения, представляющего результаты или комбинацию результатов для произошедшего компонента (?Every effect is expressed as a Boolean expression representing results, or a combination of results, for the component having occurred). Модель обычно представлена как логический граф, связывающий производные логические выражения ввода и вывода с использованием логических операторов:
- И (AND);
- ИЛИ (OR);
- Истина, если не все входные данные верны («не оба») (NAND);
- Истина, когда ни один из входов не является истиной ("ни один") (NOR);
- НЕ (NOT).
Cause-Effect Graph также известен как диаграмма Исикавы, поскольку он был изобретен Каору Исикава, или как диаграмма рыбьей кости из-за того, как он выглядит.
Граф причинно-следственных связей похож на Decision Table и также использует идею объединения условий. И иногда они описываются как один метод. Но если между условиями существует много логических зависимостей, может быть проще их визуализировать на cause-effect graph.
Syntax testing
Синтаксическое тестирование (syntax testing): Разработка тестов методом черного ящика, в которой тестовые сценарии строятся на основе области определения входящих и/или выходных значений. (ISTQB)
Синтаксическое тестирование используется для проверки формата и правильности входных данных в случаях символьных текстовых полей, проверки соответствия формату файла, схеме базы данных, протоколу и т.д., при этом данные могут быть формально описаны в технических или установленных и определенных обозначениях, таких как BNF (Форма Бэкуса - Наура).

Как правило, синтаксические тесты автоматизированы, так как они предполагают создание большого количества кейсов. Синтаксис тестируется с использованием двух условий:
- Валидные: Проверка нормального состояния с использованием покрывающего набора путей синтаксического графа для минимально необходимых требований (?Testing the normal condition using the covering set of paths of the syntax graph, for the minimum necessary requirements). Иными словами находим возможные варианты значений, допускаемые отдельными элементами определения BNF, а затем разрабатываем кейсы, чтобы просто охватить эти варианты;
- Невалидные: Проверка мусорных условий (garbage condition)* с использованием недопустимого набора входных данных.
Примечание *: Мусорные условия - это метод проверки устойчивости системы к неверным или грязным данным. Условие выполняется путем предоставления в систему грязных данных (недопустимых данных), которые не поддерживаются указанным форматом и грамматикой синтаксиса. Для создания таких данных мы определяем и применяем возможные мутации (например, отсутствующий элемент, нежелательный дополнительный элемент, недопустимое значение для элемента и т. д.) к отдельным элементам определения BNF. Затем мы разрабатываем наши кейсы, применяя мутации, которые могут давать отличительные результаты (случаи, которые приводят к действительным комбинациям, исключаются).
Check List Based Testing
Тестирование на основе контрольного списка (чеклиста) выполняется с использованием предварительно подготовленного опытными тестировщиками чеклиста, который продолжает обновляться с учетом любых новых дефектов, обнаруженных при выполнении контрольных примеров контрольного списка. При любых изменениях в продукте прогоняется быстрый чеклист, чтобы убедиться, что из-за изменений не возникло новых дефектов. Этот контрольный список не имеет отношения к пользовательским историям.
User Journey Test
User Journey test, как следует из названия, охватывает полное путешествие пользователя по системе. Он охватывает сквозные тесты, из-за которых процент покрытия тестами больше по сравнению с другими методами. Этот метод помогает уменьшить количество тестовых примеров, поскольку тестовые примеры являются исчерпывающими и охватывают большую часть функциональности в одном сценарии. Сценарии написаны для самого сложного путешествия. Тесты взаимодействия с пользователем не связаны с пользовательскими историями (user stories).
User Story Testing (Agile)
Пользовательская история - это краткое и простое описание требований клиентов или конечного пользователя. Пользовательские истории написаны владельцем продукта (Product owner), поскольку именно он получает от клиента информацию о продукте, который будет создан. Если пользовательская история большая, она разбивается на несколько более мелких историй. Истории пользователей записываются на учетных карточках и вывешиваются на стене для обсуждения. Обсуждая важные аспекты функции, выберите те, которые в дальнейшем используются в пользовательской истории. Приемочные испытания - это заключительный этап, на котором продукт принимает заказчик после того, как он соответствует всем критериям выхода. Критерии приемлемости определяются владельцем продукта, заказчик на поставку также может привлекать разработчиков, определяя то же самое.
Exhaustive testing
Исчерпывающее тестирование (exhaustive testing): Методика тестирования, в которой набор тестов включает в себя все комбинации входных данных и предусловий. (ISTQB)
Исчерпывающее тестирование (Exhaustive testing - ET) - это крайний случай. В пределах этой техники вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода почти всегда не представляется возможным, из-за огромного количества входных значений.
Dynamic - Experience based
Error Guessing
Предположение об ошибках (EG - error guessing): Метод проектирования тестов, когда опыт тестировщика используется для предугадывания того, какие дефекты могут быть в тестируемом компоненте или системе в результате сделанных ошибок, а также для разработки тестов специально для их выявления. (ISTQB)
Предугадывание ошибки (Error Guessing - EG). Это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы "предугадать" при каких входных условиях система может выдать ошибку. Например, спецификация говорит: "пользователь должен ввести код". Тест аналитик, будет думать: "Что, если я не введу код?", "Что, если я введу неправильный код? ", и так далее. Это и есть предугадывание ошибки.
Некоторые факторы использующиеся при Error Guessing:
- Уроки, извлеченные из прошлых релизов;
- Исторические знания;
- Интуиция;
- Тикеты с прода;
- Review checklist;
- Пользовательский интерфейс приложения;
- Отчеты о рисках программного обеспечения;
- Тип данных, используемых для тестирования;
- Общие правила тестирования;
- Результаты предыдущих тестов;
- Знание об AUT (тестируемое приложение);
Исследовательское тестирование (Exploratory testing)
Исследовательское тестирование (exploratory testing): Неформальный метод проектирования тестов, при котором тестировщик активно контролирует проектирование тестов в то время, как эти тесты выполняются, и использует полученную во время тестирования информацию для проектирования новых и улучшенных тестов. (Bach)
Исследовательское тестирование (exploratory testing): Тестирование, основанное на опыте, при котором тестер спонтанно разрабатывает и выполняет тестирования на основе существующих соответствующих знаний тестера, предшествующих исследований элемента тестирования (включая и результаты предыдущих тестирований) и эвристических "эмпирических правил" для общего поведения программного обеспечения и типов отказа. Примечание - Исследовательское тестирование направлено на выявление скрытых свойств (включая и скрытое поведение), которые сами по себе, с одной стороны, вполне возможно, безобидны, но, с другой стороны, могут повлиять на другие свойства тестируемого программного обеспечения и тем увеличить риск того, что программное обеспечение перестанет работать. (ГОСТ 56920)
Исследовательское Тестирование - одновременно является и техникой, и видом тестирования. В общем виде мы так или иначе всегда используем комбинацию сценарного и исследовательского подходов. Exploratory testing подразумевает под собой одновременно изучение проекта, функционала, тест-дизайн в уме и тут же исполнение тестов, после чего данный цикл может повторяться необходимое количество раз, каждый раз улучшая создаваемые кейсы и документируя пройденные сессии.
Джеймс Бах указал на важную характеристику исследовательского тестирования - тестировщик участвует когнитивно. Он активно, целенаправленно, с любопытством исследует тестируемое программное обеспечение, всегда принимая на себя ответственность каждую минуту решать, какой путь к тому, что он выбрала для исследования, является наиболее многообещающим. Нет никаких искусственных ограничений на разведку. Тестировщик может свободно использовать любые доступные источники информации, включая спецификации, записи службы технической поддержки, реализации сопоставимого программного обеспечения конкурентами и (конечно) эксперименты (тесты), которые эмпирически раскрывают информацию. Нет никаких ограничений на методы тестирования, которые могут использовать исследователи - например, любая степень автоматизации подойдет. Однако исследователь не просто перезапускает старые тесты, а тестирует чтобы учиться. Вероятно, он будет внимательно изучать поведение программы во время ее тестирования, ища новые идеи о том, как она может выйти из строя, как ее можно было бы в дальнейшем протестировать или измерить, и насколько полезны эти тесты на данном этапе разработки. Выполнение тестов можно автоматизировать, а мышление - нет. Антитезой исследования является тестирование по сценарию, в котором тестировщик (или машина) следует набору процедур, изложенных давно, сравнивая наблюдаемое поведение с любыми результатами, которые разработчик тестов считал актуальными или интересными в то время. Познание произошло тогда, а не сейчас. Объем исследования такой же, как и объем самого тестирования. Разница в том, что исследователь выполняет их в любой полезной последовательности, смешивая исследование, дизайн, выполнение, интерпретацию и общение, чтобы постоянно открывать новую информацию и идти в ногу с текущими изменениями на рынке, платформе, дизайне и реализации тестируемого программного обеспечения.
Подход к тестированию:
- Используйте эвристики для управления тестированием;
- Выполнение и создание тест-кейсов идут рука об руку;
- Тест-кейсы продолжают развиваться на основе наблюдений и обучения тестировщиков;
- К ET могут применяться различные методы тестирования, такие как анализ граничных значений, классы эквивалентности и т. д.;
- ET можно использовать сессионно , чтобы сделать его более структурированным и сфокусированным;
- Тестировщики могут развивать свои идеи, но никогда не отклоняться от своей миссии;
- Тестирование ET не использует сценарии, а зависит от интуиции, навыков и опыта тестировщика;
Туры в исследовательском тестировании: Чтобы систематизировать исследовательское тестирование можно использовать идею туров. Туры - это идеи и инструкции по исследованию программного продукта, объединенные определенной общей темой или целью. Туры, как правило, ограничены по времени - длительность тестовой сессии не должна превышать 4 часа. Идею туров развивали в своих работах Канер, Бах, Хендриксон, Болтон, Кохл и другие. Джеймс Виттакер (James A. Whittaker), хоть и не придумал саму идею туров, но предложил свой подход к исследовательскому тестированию с использованием туров и в своей книге “Exploratory Software Testing” в доступной форме озвучил идею туров и описал сами туры.
Тур - это своего рода план тестирования, он отражает основные цели и задачи, на которых будет сконцентрировано внимание тестировщика во время сессии исследовательского тестирования. При этом Виттакер использует метафору, что тестировщик - это турист, а тестируемое приложение - это город. Обычно у туриста (тестировщика) мало времени, поэтому он выполняет конкретную задачу в рамках выбранного тура, ни на что другое не отвлекаясь. Город (ПО) разбит на районы: деловой центр, исторический район, район развлечений, туристический район, район отелей, неблагополучный район.
Свободное / Интуитивное тестирование (Adhoc, Ad-hoc Testing)
Свободное тестирование (ad hoc testing): Тестирование, выполняемое неформально; без формальной подготовки тестов, формальных методов проектирования тестов, определения ожидаемых результатов и руководства по выполнению тестирования. (ISTQB)
Парное тестирование (pair testing): Два человека (двое тестировщиков, разработчик и тестировщик, или конечный пользователь и тестировщик), работающих вместе над поиском дефектов. Обычно они работают за одним компьютером, в течение работы, передавая управление друг другу. (ISTQB)
Свободное тестирование (ad-hoc testing) - это вид тестирования, который выполняется без подготовки к тестированию продукта, без определения ожидаемых результатов, проектирования тестовых сценариев. Это неформальное, импровизационное тестирование. Оно не требует никакой документации, планирования, процессов, которых следует придерживаться при выполнении тестирования. Такой способ тестирования в большинстве случаев дает большее количество заведенных отчетов об ошибке. Это обусловлено тем, что тестировщик на первых шагах приступает к тестированию основной функциональной части продукта и выполняет как позитивные, так и негативные варианты возможных сценариев.
Чаще всего такое тестирование выполняется, когда владелец продукта не обладает конкретными целями, проектной документацией и ранее поставленными задачами. При этом тестировщик полагается на свое общее представление о продукте, сравнение с похожими продуктами, собственный опыт. Однако при тестировании ad-hoc тестировщик должен иметь полные знания и осведомленность о тестируемой системе, особенно если проект очень сложный и большой. Поэтому нужно хорошее представление о целях проекта, его назначении, основных функциях и возможностях.
Виды свободного тестирования (ad-hoc testing):
- Buddy testing - процесс, когда 2 человека, как правило разработчик и тестировщик, работают параллельно и находят дефекты в одном и том же модуле тестируемого продукта. Сразу после того, как разработчик завершает модульное тестирование, тестировщик и разработчик вместе работают над модулем. Этот вид тестирования позволяет обеим сторонам рассматривать эту функцию в более широком масштабе. Разработчик получит представление обо всех различных тестах, выполняемых тестером, а тестировщик получит представление о том, какова внутренняя конструкция, которая поможет ему избежать разработки недействительных сценариев;
- Pair testing - в этом тестировании два тестировщика (лучше с разным опытом) работают вместе над одним модулем. Идея, лежащая в основе этой формы тестирования состоит в том, чтобы заставить двух тестировщиков провести мозговой штурм идей и методов, чтобы выявить ряд дефектов. Оба могут разделять работу по тестированию и делать необходимую документацию по всем сделанным наблюдениям;
- Monkey testing - произвольное тестирование продукта с целью как можно быстрее, используя различные вариации входных данных, нарушить работу программы или вызвать ее остановку (простыми словами - сломать);
Основные преимущества ad-hoc testing:
- нет необходимости тратить время на подготовку документации;
- самые важные дефекты зачастую обнаруживаются на ранних этапах;
- часто применяется, когда берут нового сотрудника. С помощью этого метода, человек усваивает за 3 дня то, что, разбираясь тестовыми случаями, разбирал бы неделю - это называется форсированное обучение новых сотрудников;
- возможность найти трудновоспроизводимые и трудноуловимые дефекты, которые невозможно было бы найти, используя стандартные сценарии проверок;
| Adhoc Testing | Exploratory Testing |
|---|---|
| Начинается с изучения приложения, а затем - с фактического процесса тестирования | Начинается с тестирования приложения, а затем его понимания посредством исследования |
| Самостоятельный вид тестирования | Разновидность Adhoc Testing |
| Не требуется никакой документации | Обязательно наличие документации по деталям тестирования. |
| Adhoc Testing проводят тестировщики, обладающие глубокими знаниями о приложении | Для изучения приложения не обязательно иметь эксперта. |
| Тестирование начинается после того, как будут собраны все данные для проведения тестирования | Сбор данных и тестирование происходят одновременно. |
| Это работает для отрицательных сценариев тестирования | В основном это касается положительных сценариев |
| Ориентировано на улучшение процесса тестирования | Ориентировано на изучение приложения |
| Зависит от творческих способностей и интуиции тестировщика | Зависит от любопытства и понимания тестировщика |
| Нет ограничений по времени | Это ограниченный по времени метод |
Attack Testing
Атака (attack): Направленная и нацеленная попытка оценить качество, главным образом надежность, объекта тестирования за счет попыток вызвать определенные отказы. См. также негативное тестирование. (ISTQB)
_Тестирование на основе атак (attack-based testing): Методика тестирования на основе опыта, использующая программные атаки с целью провоцирования отказов, в частности - отказов, связанных с защищенностью. (ISTQB) _
Диаграмма связей — это инструмент управления качеством, основанный на определении логических взаимосвязей между различными данными. Применяется этот инструмент для сопоставления причин и следствий по исследуемой проблеме.

эквивалентные класы граничные значения
добавить еще
design table
это все specification base
нужно добавить white box техники